变压器厂家聚类分析
变压器厂家名字聚类,重建预测,可视化
这是一次对变压器的厂家名字做聚类与重建预测和可视化的尝试。使用了以下手段:
- 分词
- 短句向量化, 采用简单统计词频方式做向量,没有采用ifidf,因为效果不理想,且短句子用简单的方式效果更好
- t-sne降维,没有用过pca的原因是效果不理想,重建预测时候学习曲线非常低
- t-sne 2D可视化
- 其他探索:word2vec词频空间探索相似度高的单词,效果不理想,放弃
- 其他探索:word2vec词频空间可视化
- 重建预测,使用t-sne降维到10维度的空间做初始特征
- 简单4层神经网络,$l = |x’ - x| + \lambda*(\theta)$, lambda是常数,theta是权重
- 神经元:12+6+6+10 = 34个神经元
结果与图
-
T-SNE,2维聚类,CountVector,已更新
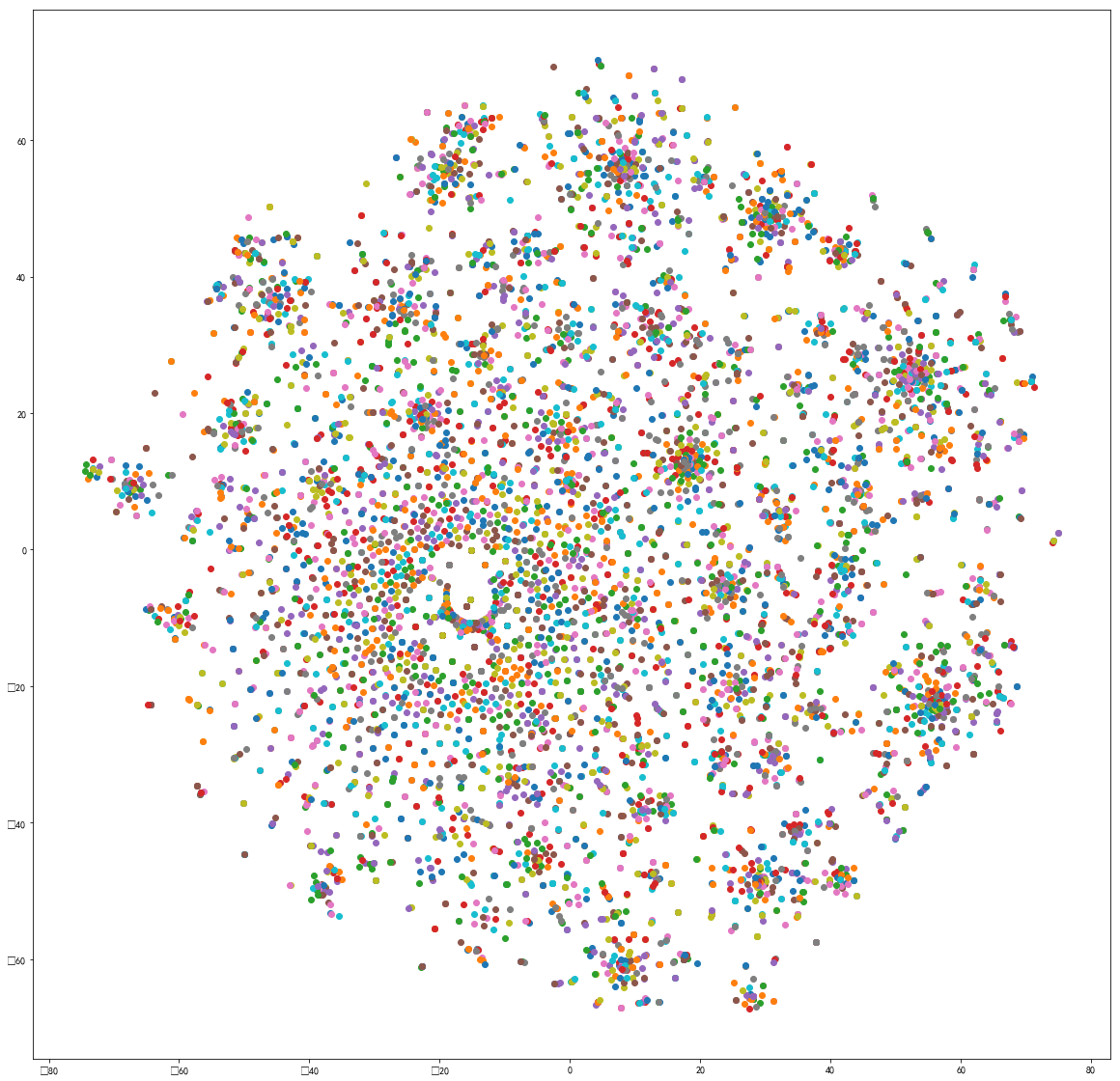
-
T-SNE,2维聚类,序号标注,CountVector,已更新
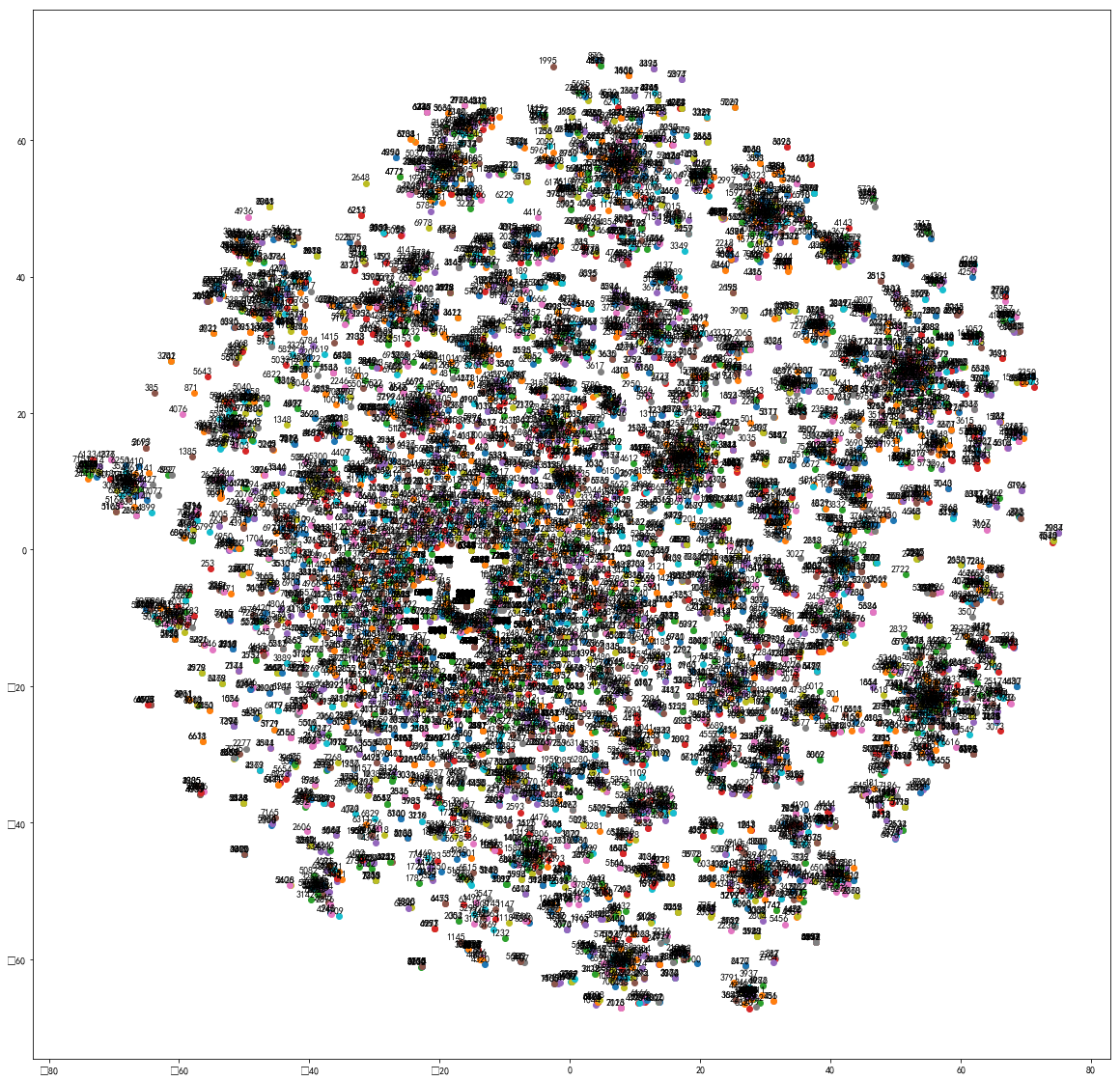
-
T-SNE,2维聚类,序号标注,TfidfVector,已过期,前面有些初始化的数据不对
-
Word2Vec词频空间可视化,这个说明不了太多问题,已过期
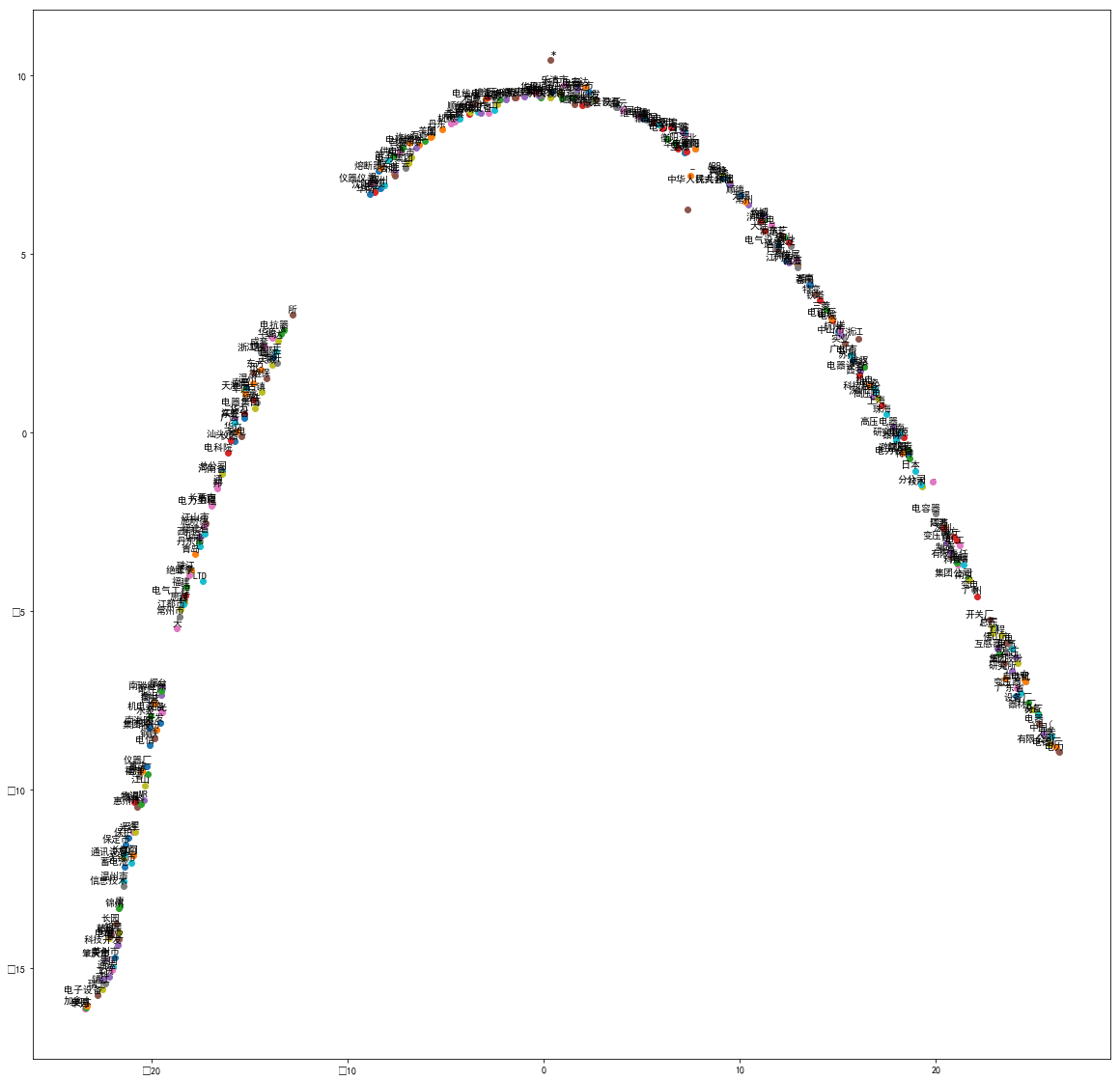
-
K-Means 40个聚类,这个说明不了太多问题,已过期

-
Autoencoder(重建预测),T-SNE,10维降维,学习曲线,横轴是尝试次数,最后稳定在92%的准确性 已更新
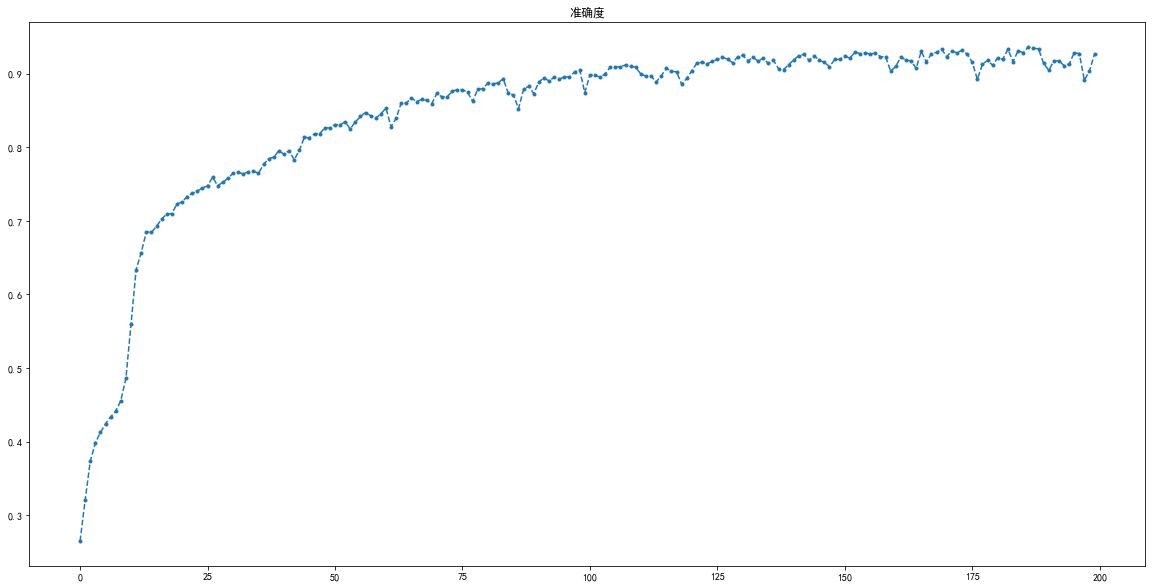
-
Autoencoder(重建预测),T-SNE,10维降维,预测与实际的L2距离, 横轴是序号,已更新
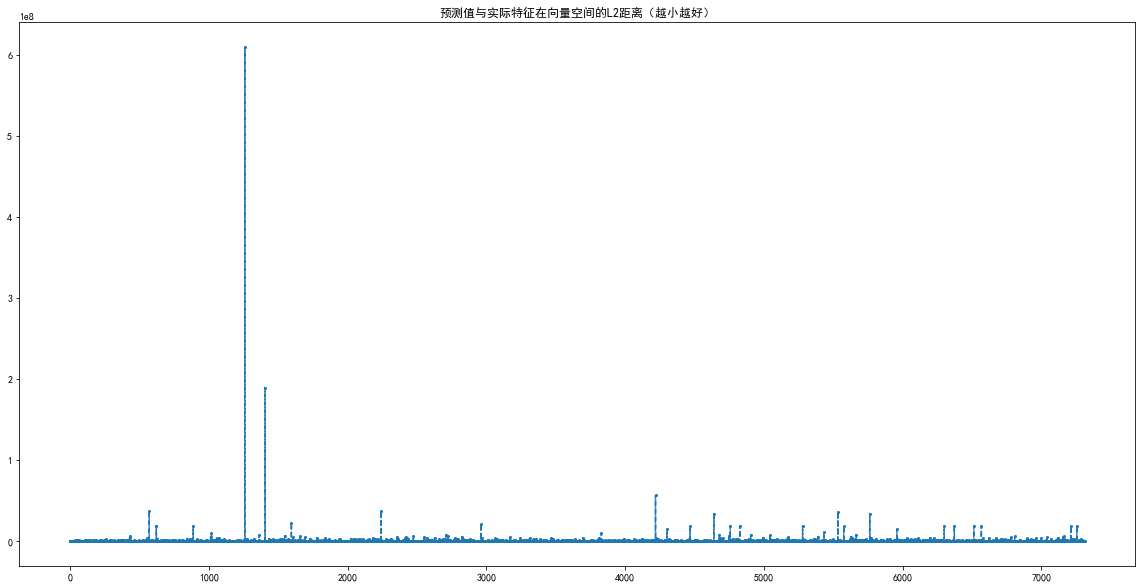
罗列部分文字结果
这里的文字结果,是取重建预测中预测的比较差的前10个。
前10个可能出现问题的厂家名字:
- 可能有问题的序列号: 5879, 序列号对应的厂家: 西安西北电力电器制造公司西安西北电力电器制造公司
- 可能有问题的序列号: 2927, 序列号对应的厂家: 广东番禺明珠电器有限责任公司 广东番禺世纪变压器有限公司
- 可能有问题的序列号: 4206, 序列号对应的厂家: 安徽赛普电气有限公司
- 可能有问题的序列号: 4277, 序列号对应的厂家: 博世(bosch)
- 可能有问题的序列号: 5108, 序列号对应的厂家: Kelong
- 可能有问题的序列号: 6129, 序列号对应的厂家: 加拿大罗杰康有限公司
- 可能有问题的序列号: 6395, 序列号对应的厂家: 金宏威
- 可能有问题的序列号: 7289, 序列号对应的厂家: 新安宝
- 可能有问题的序列号: 2377, 序列号对应的厂家: LG牌电视机
- 可能有问题的序列号: 5536, 序列号对应的厂家: 杭州德赢科技有限公司
使用余弦像似性作为衡量标准,取它们对应的相似的前4个:
- [‘西安西北电力电器制造公司’ ‘西安西北电力电器制造公司西安西北电力电器制造公司’ ‘西安电力制造公司’ ‘西安翰德电力电器制造有限公司’]
- [‘广东番禺明珠电器有限责任公司 广东番禺世纪变压器有限公司’ ‘广州番禺明珠电器有限责任公司’ ‘广东番禺电缆实业有限公司’ ‘广东番禺电气设备制造有限公司’]
- [‘安徽赛普电气有限公司’ ‘安徽泰隆电气有限公司’ ‘安徽巨森电气有限公司’ ‘安徽龙波电气有限公司’]
- [‘博世(bosch)’ ‘博世’ ‘BOSCH’ ‘BOSCH(中国)’]
- [‘Kelong’ ‘KELONG’ ‘杭州华立仪表有限公司’ ‘河北保定特种变压器厂’]
- [‘加拿大罗杰康有限公司’ ‘加拿大’ ‘加拿大HARRIS’ ‘罗杰康(中国)有限公司’]
- [‘金宏威’ ‘深圳市金宏威技术股份有限公司’ ‘深圳市金宏威实业发展有限公司’ ‘杭州永德电气公司’]
- [‘新安宝’ ‘深圳市新安电力设备厂’ ‘杭州华立仪表有限公司’ ‘杭州永德电气公司’]
- [‘LG牌电视机’ ‘LG’ ‘三星牌电视机’ ‘LG公司’]
- [‘杭州德赢科技有限公司’ ‘杭州传恒科技有限公司’ ‘杭州鸿程科技有限公司’ ‘杭州易斯特科技有限公司’]
结论
这是一个发现异常的问题,因为没有标签所以是无监督学习。去除冗余,样本的多样性依旧较大,在数据量比较小的情况下(7k)去发现文字的异常是意见比较困难的事情。这里尝试了多种方式去可视化,效果不是特别明显,也从侧面验证了当特征值数量大而样本数量较小的时,数据挖掘欠拟合的问题。